Example Workflow¶
There are example workflows in examples/flows/ that could make use of the tasks and flows
defined in QBitBridge.
We discuss a multi-vqpu example here see multi_vqpu_cpugpu_workflow.py in detail here.
This flow uses some basic build-block tasks and flows defined in qbitbridge/vqpuflows.py.
The Prefect view is of this flow is shown below.
Video of QbitBridge in action. An example of a multi-vQPU workflow as visualized by the Prefect UI.¶
This flow demonstrates running several vQPUs that await circuits being sent to them before being shutdown along with other vQPUs that are ideal and shutdown after a certain amount of time. It also spawns CPU-oriented and GPU-oriented flows and how to run these flows in an asynchronous fashion.
We strongly suggest you alter the CPU and GPU commands before trialling this workflow if you would like to test it. The
code as it stands also uses a cluster specific yaml file where the python path variable has been updated to include the
absolute path of the workflow/ directory.
This example showcases a few key things:
Use of the HybridQuantumWorkflowBase class to manage a flow
Use of basic flows like gpu_workflow being launched with a DaskTaskRunner that differs form the parent flow runner.
Use of asynchronous flows launched using asyncio.TaskGroup
Multiple vQPUs being launched and awaiting circuits
Circuits being sent to several different vQPUs from a single flow
To get a better understanding of the workflow, let’s break it down.
Main flow¶
The main workflow, Multi-vQPU Test, launches several other flows, each with appropriate DaskTaskRunners which effectively submit Slurm jobs with appropriate resource requests. If we look at the code
@flow(
name="Multi-vQPU Test",
flow_run_name="Mulit-vQPU_test_{myqpuworkflow.vqpu_ids}_on-{date:%Y-%m-%d:%H:%M:%S}",
description="Running a multi-(v)QPU+CPU+GPU hybrid workflow",
retries=3,
retry_delay_seconds=10,
log_prints=True,
)
async def workflow(
myqpuworkflow: HybridQuantumWorkflowBase,
circuitargs: str,
cpuexecs: List[str],
cpuargs: List[str],
gpuexecs: List[str],
gpuargs: List[str],
vqpu_walltimes: List[float],
date: datetime.datetime = datetime.datetime.now(),
):
"""
@brief overall workflow for hydrid multi-(v)QPU+CPU+GPU
"""
MAXWALLTIME: float = 86400.0
if len(vqpu_walltimes) < len(myqpuworkflow.vqpu_ids):
num_to_add = len(myqpuworkflow.vqpu_ids) - len(vqpu_walltimes)
for i in range(num_to_add):
vqpu_walltimes.append(MAXWALLTIME)
logger = get_run_logger()
logger.info("Running hybrid multi-(v)QPU workflow")
vqpuflows = dict()
circuits = dict()
circuitflows = dict()
for vqpu_id in myqpuworkflow.vqpu_ids:
if vqpu_id > 1 and vqpu_id < 3:
circuits[f"vqpu_{vqpu_id}"] = [noisy_circuit, noisy_circuit, noisy_circuit]
elif vqpu_id > 3:
circuits[f"vqpu_{vqpu_id}"] = [(noisy_circuit, postprocessing_histo_plot)]
else:
circuits[f"vqpu_{vqpu_id}"] = [(noisy_circuit, postprocessing_histo_plot)]
# lets define the flows with the appropriate task runners
# this would be for the real vqpu
vqpuflows[f"vqpu_{vqpu_id}"] = launch_vqpu_workflow.with_options(
task_runner=myqpuworkflow.gettaskrunner("vqpu"),
)
circuitflows = circuits_with_nqvpuqs_workflow.with_options(
task_runner=myqpuworkflow.gettaskrunner("circuit"),
)
othercircuitflows = cpu_with_random_qpu_workflow.with_options(
task_runner=myqpuworkflow.gettaskrunner("cpu"),
)
# silly change so that any vqpu_ids past 3 are
# not provided to circuitflows but rather
# set aside to the cpu flow that can spawn vqpus
circ_vqpu_ids = list()
other_vqpu_ids = list()
for vqpu_id in myqpuworkflow.vqpu_ids:
if vqpu_id >= 3:
other_vqpu_ids.append(vqpu_id)
else:
circ_vqpu_ids.append(vqpu_id)
async with asyncio.TaskGroup() as tg:
# either spin up real vqpu
for i in range(len(myqpuworkflow.vqpu_ids)):
vqpu_id = myqpuworkflow.vqpu_ids[i]
vqpu_walltime = vqpu_walltimes[i]
tg.create_task(
vqpuflows[f"vqpu_{vqpu_id}"](
myqpuworkflow=myqpuworkflow,
walltime=vqpu_walltime,
vqpu_id=vqpu_id,
)
)
# silly change so that any vqpu_ids past 3 are
# not provided to circuitflows but rather
# set aside to the cpu flow that can spawn vqpus
tg.create_task(
circuitflows(
myqpuworkflow=myqpuworkflow,
circuits=circuits,
vqpu_ids_subset=circ_vqpu_ids,
arguments=circuitargs,
)
)
tg.create_task(
othercircuitflows(
myqpuworkflow=myqpuworkflow,
circuits=circuits,
vqpu_ids_subset=other_vqpu_ids,
circuitargs=circuitargs,
cpuexecs=cpuexecs,
cpuargs=cpuargs,
gpuexecs=gpuexecs,
gpuargs=gpuargs,
)
)
for k in myqpuworkflow.events.keys():
myqpuworkflow.events[k].clean()
logger.info("Finished hybrid multi-(v)QPU workflow")
We can several key features:
The flow is passed a HybridQuantumWorkflowBase instance. This instance is passed along to every subflow that is called.
Subflow as defined are never called directly. Instead, a flow instance is create from a flow definition using the with_options to set the task_runner to an appropriate task runner.
Sublows instances are called from within an asycio.TaskGroup to run the flows concurrently.
Subflows¶
The subflows called by the parent flow are
qbitbridge.vqpuflow.launch_vqpu_workflow.with_options - which launches a vQPU service that can receive circuits and will return results to the appropriate calling circuit submission process. This flow runs a launch_vqpu` task, a run_vqpu` task and a shudown_vqpu:
@flow() async def launch_vqpu_workflow( myqpuworkflow: HybridQuantumWorkflowBase, vqpu_id: int = 1, ) -> None: future = await launch_vqpu.submit( myqpuworkflow=myqpuworkflow, ..., ) await future.result() # run vqpu till shut-down signal received future = await run_vqpu.submit( myqpuworkflow=myqpuworkflow, vqpu_id=vqpu_id, walltime=walltime ) await future.result() # once the run has finished, shut it down future = await shutdown_vqpu.submit(myqpuworkflow=myqpuworkflow, vqpu_id=vqpu_id) await future.result()
qbitbridge.vqpuflow.circuits_with_nqvpuqs_workflow - runs circuits on a set of vQPUs once the vQPUs are available. A dictionary of vqpu ids and the circuits that they will run is provided. The flow makes use of the qbitbridge.vqpuflow.run_circuits_once_vqpu_ready task.
@flow() async def circuits_with_nqvpuqs_workflow( myqpuworkflow: HybridQuantumWorkflowBase, circuits, ..., ) -> Dict[str, List[Dict[str, Any]]]: async with asyncio.TaskGroup() as tg: # either spin up real vqpu for vqpu_id in vqpu_ids_subset: tasks[vqpu_id] = tg.create_task( run_circuits_once_vqpu_ready( myqpuworkflow=myqpuworkflow, circuits=circuits[f"vqpu_{vqpu_id}"], vqpu_id=vqpu_id, arguments=arguments, circuits_complete=circuits_complete, ) ) results = {f"vqpu_{name}": task.result() for name, task in tasks.items()} logger.debug(results) return results
qbitbridge.vqpuflow.run_circuits_once_vqpu_ready task that handles ciccuit submission to to a given remote vqpu service (can also be a real qpu). It waits for the service to be running. Once all circuits have been submitted, it can tell the vqpu to shutdown if the vqpu is listening for all circuits submitted event.
@task() async def run_circuits_once_vqpu_ready( myqpuworkflow: HybridQuantumWorkflowBase, circuits, circuits_complete: bool = True, ): key = f"vqpu_{vqpu_id}" remote = await myqpuworkflow.getremoteaftervqpulaunch(vqpu_id=vqpu_id) logger.info(f"{key} running, submitting circuits ...") for c in circuits: result = await run_circuitandpost_vqpu.fn( myqpuworkflow=myqpuworkflow, circuit=c, vqpu_id=vqpu_id, arguments=arguments, remote=remote, ) results.append(result) # if circuits completed should trigger a shutdown of the vqpu, then set the circuits complete event if circuits_complete: myqpuworkflow.events[f"qpu_{vqpu_id}_circuits_finished"].set() return results
cpu_with_random_qpu_workflow - a flow that also creates several subflows dynamically. The key feature of this flow is similar to the main workflow: creating flow instances with appropriate task runners and submitting these flow instances to run within asyncio.TaskGroup
@flow() async def cpu_with_random_qpu_workflow( myqpuworkflow: HybridQuantumWorkflowBase, ..., ) -> None: # run cpu tasks using this flows taskrunner for exec, args in zip(cpuexecs, cpuargs): logger.info(f"Running {exec} with {args}") futures.append( await run_cpu.submit(myqpuworkflow=myqpuworkflow, exec=exec, arguments=args) ) for f in futures: await f.result() circflow = circuits_vqpu_workflow.with_options( task_runner=myqpuworkflow.gettaskrunner("circuit"), ) # dynamically launch a gpu flow with the gpu task runner # and cpu flows with the cpu task runner # or submit circuits to a vqpu async with asyncio.TaskGroup() as tg: for i in range(max_num_gpu_launches): if np.random.uniform() > 0.5: tasks["gpu"].append( tg.create_task( gpu_workflow.with_options( task_runner=myqpuworkflow.gettaskrunner("gpu") )( myqpuworkflow=myqpuworkflow, execs=gpuexecs, arguments=gpuargs, ) ) ) if np.random.uniform() > 0.75: tasks["cpu"].append( tg.create_task( cpu_workflow.with_options( task_runner=myqpuworkflow.gettaskrunner("cpu") )( myqpuworkflow=myqpuworkflow, execs=cpuexecs, arguments=cpuargs, ) ) ) # either spin up real vqpu for vqpu_id in vqpu_ids_subset: if np.random.uniform() > 0.5: tasks["qpu"][vqpu_id] = tg.create_task( circflow( myqpuworkflow=myqpuworkflow, vqpu_id=vqpu_id, circuits=circuits[f"vqpu_{vqpu_id}"], arguments=circuitargs, circuits_complete=True, ) ) else: # note that since the workflow is also designed to have qpu events, # if explicitly waiting for event, use qpu_<id>_* await myqpuworkflow.events[f"qpu_{vqpu_id}_launch"].wait() myqpuworkflow.events[f"qpu_{vqpu_id}_circuits_finished"].set()
Overall flow¶
The dynamic nature of the workflow means it can be difficult to visualise it with a directed acyclic graph (DAG). The use of asynchronous tasks and flows means it is not possible to use in-built tools to create a DAG. Even the Prefect UI does not capture the dependency between tasks since some tasks in one flow, specifically the circuit submission ones will not start running till an event is created in another flow, namely the vQPU flows. These circuits can trigger a vQPU shutdown as well.
However, the full set of interdependencies need not be fully known a-priori, just key interdependencies between tasks within the same flow (by ordering the of tasks) and across flows (by setting events). An example of the flowchart for the multi-vQPU workflow (here limited to two vQPUs) is presented below, which illustrates the communication managed by QBitBridge, Prefect, and the (v)QPU API calls.
![# dot file of a multi-vqpu-workflow
digraph G {
size ="32,32";
# rankdir=TB;
subgraph vqpu_flow_0{
label = "vQPU 0 flow"
fontsize=18;
fontname="arial";
shape=box;
style="filled,solid";
color="black";
fillcolor="#f5f5f5"
labelloc="t";
penwidth=2.0;
node [fontname="times",
shape=box,
penwidth=0.0
style="filled,solid";
color="#fdc46f";
fillcolor="#fdc46f"
labelloc="c"
width=2.5,
height=0.5,
fontsize=18;
fixedsize=true,
];
vqpu_0_launch [label="vQPU-0 launch" ];
vqpu_0_run [label="vQPU-0 run" ];
vqpu_0_shutdown [label="vQPU-0 shutdown" ];
}
subgraph vqpu_flow_1{
label = "vQPU 1 flow"
fontsize=18;
fontname="arial";
shape=box;
style="filled,solid";
color="black";
fillcolor="#f5f5f5"
labelloc="t";
penwidth=2.0;
node [fontname="times",
shape=box,
penwidth=0.0
style="filled,solid";
color="#fdc46f";
fillcolor="#fdc46f"
labelloc="c"
width=2.5,
height=0.5,
fontsize=18;
fixedsize=true,
];
vqpu_1_launch [label="vQPU-1 launch" ];
vqpu_1_run [label="vQPU-1 run" ];
vqpu_1_shutdown [label="vQPU-1 shutdown" ];
}
subgraph circuit_flow_0{
label = "vQPU 1 flow"
fontsize=18;
fontname="arial";
shape=box;
style="filled,solid";
color="black";
fillcolor="#f5f5f5"
labelloc="t";
penwidth=2.0;
node [fontname="times",
shape=box,
penwidth=0.0
style="filled,solid";
color="#6ffd6fff";
fillcolor="#6ffd6fff"
labelloc="c"
width=3,
height=0.75,
fontsize=18;
fixedsize=true,
];
circuit_start [label="Circuit : start" ];
circuit_wait_vqpu_0 [label="Circuit :\nwait for vQPU-0" ];
circuit_wait_vqpu_1 [label="Circuit :\nwait for vQPU-1" ];
circuit_run [label="Circuits: run" ];
circuit_finish [label="Circuits: finish" ];
}
subgraph cpu_flow{
label = "CPU flow"
fontsize=18;
fontname="arial";
shape=box;
style="filled,solid";
color="black";
fillcolor="#f5f5f5"
labelloc="t";
penwidth=2.0;
node [fontname="times",
shape=box,
penwidth=0.0
style="filled,solid";
color="#3c7de6";
fillcolor="#3c7de6"
labelloc="c"
width=3,
height=0.5,
fontsize=18;
fixedsize=true,
];
cpu_start [label="CPU flow : start" ];
cpu_run [label="CPU flow: run" ];
cpu_circuit [label="CPU flow: run circuits" ];
cpu_finish [label="CPU flow: finish" ];
}
subgraph gpu_flow{
label = "GPU flow"
fontsize=18;
fontname="arial";
shape=box;
style="filled,solid";
color="black";
fillcolor="#f5f5f5"
labelloc="t";
penwidth=2.0;
node [fontname="times",
shape=box,
penwidth=0.0
style="filled,solid";
color="#3ce6e6ff";
fillcolor="#3ce6e6ff";
labelloc="c"
width=3,
height=0.5,
fontsize=18;
fixedsize=true,
];
gpu_start [label="GPU flow : start" ];
gpu_run [label="GPU flow: run" ];
gpu_finish [label="GPU flow: finish" ];
}
{rank=same;vqpu_0_launch;vqpu_1_launch;cpu_start;}
{rank=same;vqpu_0_run;circuit_run;vqpu_1_run;cpu_circuit;}
{rank=same;cpu_run;gpu_start;}
// {rank=same;vqpu_0_shutdown;vqpu_1_shutdown;}
# connections
vqpu_0_launch -> vqpu_0_run
vqpu_0_run -> vqpu_0_shutdown
vqpu_1_launch -> vqpu_1_run
vqpu_1_run -> vqpu_1_shutdown
circuit_start -> circuit_wait_vqpu_0
circuit_start -> circuit_wait_vqpu_1
circuit_wait_vqpu_0:s -> circuit_run:n
circuit_wait_vqpu_1:s -> circuit_run:n
circuit_run -> circuit_finish
cpu_start -> cpu_run
cpu_run:e -> gpu_start:w
cpu_run:w -> cpu_circuit
cpu_run -> cpu_finish
gpu_start -> gpu_run
gpu_run -> gpu_finish
# connects between flows
vqpu_0_launch -> circuit_wait_vqpu_0:w [label = "vQPU-start event", color=blue, style=dashed, fontcolor=blue]
vqpu_1_launch -> circuit_wait_vqpu_1:w [label = "vQPU-start event", color=blue, style=dashed, fontcolor=blue]
circuit_finish:n -> vqpu_0_run:s [label = "circuit complete\n vQPU shutdown event", color=blue, style=dashed, fontcolor=blue]
circuit_finish:n -> vqpu_1_run:s [label = "circuit complete\n vQPU shutdown event", color=blue, style=dashed, fontcolor=blue]
vqpu_1_launch -> cpu_circuit:w [label = "vQPU-start event", color=blue, style=dashed, fontcolor=blue]
vqpu_0_run:e -> circuit_run:w [label = "vQPU circuits\n results", dir=both, color="#ff5100ff", style=dotted, fontcolor="#ff5100ff", penwidth=2]
vqpu_1_run:e -> circuit_run:w [label = "vQPU circuits\n results", dir=both, color="#ff5100ff", style=dotted, fontcolor="#ff5100ff", penwidth=2]
vqpu_1_run:e -> cpu_circuit:w [label = "vQPU circuits\n results", dir=both, color="#ff5100ff", style=dotted, fontcolor="#ff5100ff", penwidth=2]
}](_images/graphviz-ea9202fc0cc42697507b225b57af3168ae3e5a64.png)
Outline of the multi-vQPU workflow. Flows are colour-coded according to the resources used. We also show the events that communicate across flows as blue arrows and communication that occurs between flows and the remote vQPU service (which can be also replaced by a real QPU) as red arrows.¶
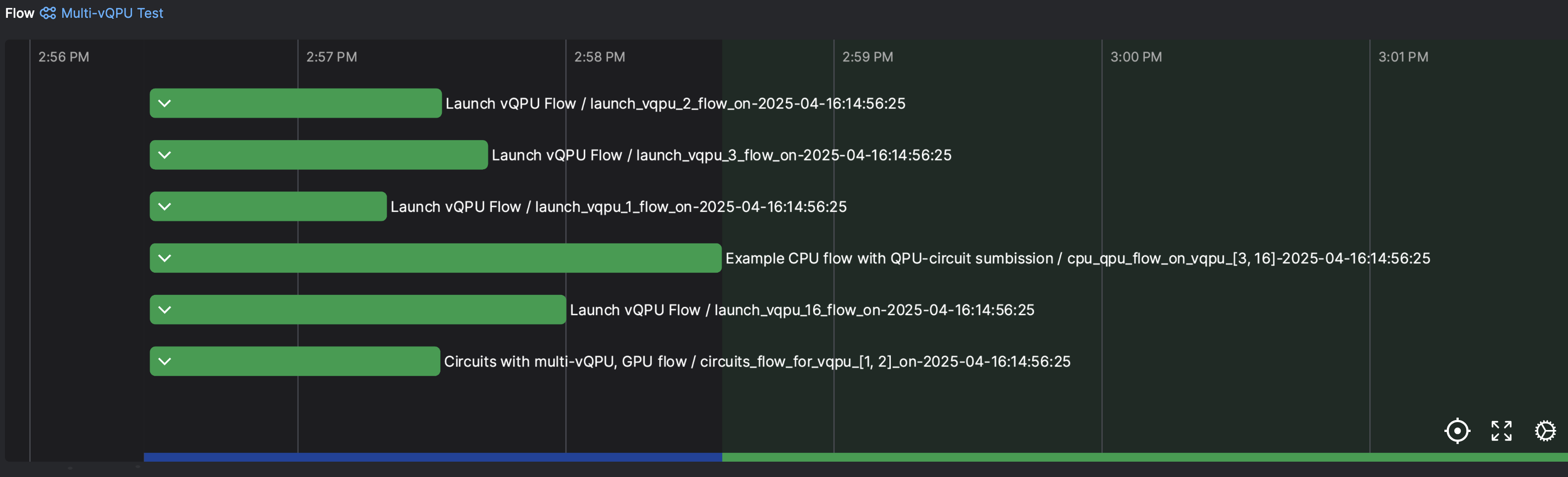
Prefect View. An example of a multi-vQPU workflow as visualized by the Prefect UI.¶
The dynamic nature of the flow means that the exact number of flows and the inter-flow communication will change each time it is run.